





I. Configuration logicielle▲
Les logiciels utilisés dans ce tutoriel sont les suivants :
- Eclipse Neon ;
- Karaf 4.1.0 ;
- JDK 1.8.
Les APIApplication Programming Interface Java utilisées sont :
- JPAJava Persistence API 2 ;
- Jackson.
Les frameworks utilisés :
- Hibernate ;
- Apache CXF.
II. Rappel▲
II-A. Les différentes parties d'un projet▲
En règle général, nous pouvons décomposer un projet en différentes parties :
- La partie « persistance »
Également appelée « couche DAO », elle joue le rôle d'interface entre la base de données et les autres principales parties (« métier » et « intégration »). On y définit le modèle des données (généralement composé de POJO et d'interfaces de persistance) ainsi que la logique de persistance en fonction de la ou les technologies utilisées.
Quelles que soient les technologies utilisées, on réutilise, dans cette logique de persistance, les POJO et les interfaces définis dans le modèle des données.
Cette partie « persistance » est souvent appelée par la partie « métier » et quelquefois, lorsqu'il s'agit uniquement de sélectionner des informations sans y apporter de plus-value métier, par la partie « intégration » ; - La partie « métier »
On y définit les règles métier qui s'appliquent avant de modifier des données dans la source de données ou avant d'envoyer les données issues de la source de données vers le client qui les a demandées ; - La partie « intégration »
Elle joue le rôle d'interface entre la couche métier et l'interface utilisateur. Elle peut contenir des routes, des services REST, des services SOAP…
Comme nous l'avons signalé plus haut, elle peut aussi accéder à la couche « persistance » si aucune plus-value métier n'est exigée sur les données qu'elle demande. Dans ce cas, il s'agira d'effectuer une sélection sur le jeu de données ; en cas d'insertion ou de modification des données, la partie métier devrait systématiquement être appelée pour effectuer les vérifications d'usage ; - La partie « interface utilisateur »
Il s'agit de ce que l'utilisateur voit à l'écran.
II-B. Service OSGI▲
Avant de lire ce tutoriel, nous ne saurons trop vous conseiller de lire les tutoriels précédents qui traitent du développement de services web OSGIOpen Services Gateway Initiative RESTRepresentational State Transfer ou SOAPSimple Object Access Protocol et de leur déploiement dans Karaf :
https://olivier-rozier.developpez.com/tutoriels/rest/restful-karaf-multibundle/
https://olivier-rozier.developpez.com/tutoriels/soap/soap-karaf-multibundle/
Pour rappel, un service OSGIOpen Services Gateway Initiative est une instance d'objet Java enregistrée dans un framework OSGIOpen Services Gateway Initiative avec un ensemble de propriétés. N'importe quel objet Java peut être enregistré en tant que service, mais seul est vu comme service OSGIOpen Services Gateway Initiative un objet qui implémente une interface.
Le client d'un service OSGIOpen Services Gateway Initiative est toujours un « bundle » OSGIOpen Services Gateway Initiative. C'est-à-dire un morceau de code Java exposant et/ou utilisant des services.
Chaque bundle peut enregistrer zéro ou plusieurs services et peut utiliser zéro ou plusieurs services.
Les principaux avantages des services OSGI sont :
-
La facilité de modularisation des applications :
- Le déploiement de nouveaux services sur le serveur d'application se fait à chaud. Il n'y a, en aucun cas, besoin de redémarrer la plate-forme pour que les nouveaux services soient pris en compte ;
- Lors de l'installation d'une nouvelle version d'un service, seuls les services configurés pour travailler avec cette nouvelle version l'utiliseront. Les autres continueront d'utiliser l'ancienne version qui subsistera sur le serveur (à moins qu'on les supprime) ;
- Différentes versions d'un même service peuvent cohabiter sur le serveur.
- Seuls les packages exportés par un « bundle » sont visibles des autres bundles qui peuvent alors les importer. Le développeur d'un « bundle » peut choisir d'exporter seulement certains « package » sous certaines versions, empêchant ainsi les problèmes de chargement de classes Java tout en sécurisant son service.
- La découverte dynamique des services par d'autres services.
III. Les bonnes pratiques de OSGI▲
Structurer un projet OSGIOpen Services Gateway Initiative, c'est avant tout respecter les bonnes pratiques suivantes :
-
Permettre un faible couplage entre les clients et les fournisseurs de l'API.
Les packages et les bundles doivent être versionnés afin que les clients puissent se protéger de tout changement d'API qui pourrait l'empêcher de fonctionner.
Les versions d'un projet se notent sous la syntaxe « major.minor.micro » dans laquelle « major », « minor » et « micro » sont des nombres entiers naturels (un nombre entier naturel est un nombre entier supérieur ou égal à zéro) :- Un changement de version « major » contraint à la recompilation des clients de l'API pour garantir leur bon fonctionnement. Par exemple, la suppression d'une interface ou d'une méthode doit entraîner un changement de version « major » ;
- Un changement de version « minor » indique que l'API a été améliorée , mais qu'elle ne nécessite pas une recompilation des clients. Les clients fonctionneront tout aussi bien avec cette version de l'API.
Le type de modification qui concerne le changement de version « minor » est, par exemple, l'ajout d'interfaces ou de méthodes ; -
Un changement de version « micro » indique qu'un changement a été appliqué dans l'API mais qu'il ne modifie en rien son utilisation et sa philosophie.
Par exemple, on changera la version « micro » dans le cas de la résolution d'un bug.Un container OSGIOpen Services Gateway Initiative peut contenir simultanément plusieurs versions d'une API dans le « runtime ». Ces versions peuvent être utilisées simultanément par des clients différents qui auront précisé la plage de version dans laquelle ils souhaitent utiliser l'API. Souvenez-vous : nous avions évoqué cette possibilité dans notre tutoriel https://olivier-rozier.developpez.com/tutoriels/rest/restful-karaf-multibundle/#LIX ;
-
Séparer l'API de l'implémentation.
L'API et son implémentation seront dans des « bundles » séparés. Cette bonne pratique bénéficiera également de la gestion des versions que nous venons d'évoquer.
La séparation des interfaces et des classes les implémentant dans des « bundles » séparés offre davantage de flexibilité que le simple « versionning » ci-dessus.
En effet, un bundle ne contenant que des interfaces permet aux clients de l'API d'utiliser n'importe quel fournisseur de leur implémentation tout en permettant l'utilisation de plusieurs implémentations différentes à la fois.
Nous le verrons plus loin, dans l'exemple propre à ce tutoriel, avec le bundle « persistance-model », qui définit, entre autres, l'interface de persistance nommée « ServicePersistenceMarque ». On pourra implémenter cette interface en autant de classes qu'on a de technologies de persistance :- jpa ;
- sql ;
- cassandra ;
-
…
Dans notre cas, la classe « MarqueDaoImpl » du module « persistance-marque-jpa-impl » implémente l'interface « ServicePersistenceMarque » en utilisant JPA.Nous pourrions très bien développer une autre implémentation de cette interface en SQL dans un module nommé « persistance-marque-sql-impl » et les deux « bundles » « persistance-marque-jpa-impl » et « persistance-marque-sql-impl » cohabiteraient ensemble dans le container OSGIOpen Services Gateway Initiative.
Dès lors, on peut imaginer par exemple deux versions d'un même service REST : l'une utilisant une implémentation de JPA et une autre utilisant une implémentation de SQL. -
RAPPEL : Les bundles exposent leurs services aux autres bundles dans l'annuaire de services. Dans cet annuaire, un service est décrit par une interface.
Imaginons le cas où nous modifions l'implémentation d'une interface. Si nous plaçons l'interface et ses implémentations dans un même « bundle », les clients de l'API auraient besoin d'être redémarrés pour se reconnecter à un nouveau bundle contenant cette nouvelle implémentation même si l'interface n'a pas changé.
En effet, pour tenir compte des changements dans l'implémentation, il faut redéployer le « bundle ». Comme ce « bundle » contient aussi l'interface qui décrit le service dans l'annuaire de services, le service sera enregistré de nouveau sous un autre identifiant et les « bundles » l'utilisant, pour en tenir compte, devront redémarrer. Ceci entraînera alors une coupure de service alors qu'un des points positifs de la spécification OSGIOpen Services Gateway Initiative est de pouvoir effectuer les changements d'implémentation à chaud.
En revanche, en plaçant l'interface dans un bundle et l'implémentation dans un autre, les clients n'ont pas besoin d'être redémarrés pour être mis en contact avec cette nouvelle version de l'implémentation puisque l'interface ne change pas et que le bundle qui l'expose est complètement indépendant de l'implémentation.
On peut donc changer les implémentations sans avoir besoin de redémarrer les « bundles » dépendants ;
- Séparer les « entity » du modèle.
Il faut étendre aux POJO le point qui stipule qu'il est de bon aloi de séparer l'API de l'implémentation.
Par exemple, on aura un bundle dont le rôle sera de gérer la persistance. Dans ce bundle seront définies des interfaces qui feront appel à des POJO. L'erreur à éviter est, par exemple, de faire ces POJO comme des entity JPA (par exemple, contenant des annotations), ce qui reviendrait à dire que le modèle est lié à JPA. Si, plus tard ou en parallèle, on souhaite utiliser une autre technologie (NoSQL par exemple), alors, dans ce cas, il sera nécessaire de changer le modèle. Or, le plus important est d'avoir un modèle le plus générique possible non lié à l'implémentation. Pour cela, il faut se souvenir qu'une entité JPA est un exemple d'implémentation : ça ne doit donc pas faire partie du modèle.
La bonne pratique est de faire des POJO et de les étendre (« extends ») dans l'implémentation JPA. De cette manière, si vous souhaitez passer sur du NoSQL ou du big data, votre modèle sera toujours valide. Il suffira de refaire des classes qui étendent ces mêmes POJO (modèles) ;
-
Les bundles doivent être faiblement couplés et très cohésifs.
Chaque bundle doit avoir un rôle spécifique. L'objectif est de faire en sorte qu'un bundle effectue un nombre de tâches faible.
Un contre-exemple consisterait à concevoir un bundle qui gère la persistance à la fois à l'aide de l'API JPA, de sql, de Cassandra… Dans ce cas, il vaut mieux, comme dans l'exemple de ce tutoriel, définir, dans un « bundle », une interface de persistance qui sera implémentée dans différents autres « bundles » qui utiliseront respectivement soit l'API JPA, soit SQL, soit Cassandra…
Généralement la taille d'un « bundle » grossit en même temps que :- le nombre de tâches qu'il accomplit ;
- son nombre de dépendances et, par conséquent, que le nombre de « bundles » à installer. Sachant qu'un « bundles » dépend souvent d'autres « bundles », le risque de voir le nombre de dépendances explosé est réel. Il est donc important de tout faire pour limiter ce nombre de dépendances en évitant par exemple les surcouches qui non seulement introduisent des dépendances mais consomment aussi des ressources.
Un « bundle » mal conçu peut donc nécessiter le téléchargement et l'installation de plusieurs mégaoctets pour accéder à seulement une ou deux fonctions simples.
En revanche, un bundle dont le rôle est bien ciblé aura très peu de dépendances et sera plus facilement réutilisable dans d'autres applications. En outre, ceci lui évitera d'être lié à des versions spécifiques d'autres « bundles » ou « packages » ; -
Éviter les « split-packages ».
Un « split-package » est un même package qui se trouve dans au moins deux « bundles » différents.
Il faut définir toutes les classes d'un même package dans un seul « bundle ». En effet, les « bundles » importent des packages présents dans d'autres « bundles » et exportent d'autres packages. Par conséquent, chaque « bundle » déclare ses dépendances en termes de « packages » Java. Ces dépendances sont satisfaites au moment de l'exécution du containeur OSGIOpen Services Gateway Initiative.
Plusieurs « bundles » peuvent fournir un même « package ». La décision de savoir quel « bundle » fournit la dépendance est laissée à l'environnement d'exécution OSGIOpen Services Gateway Initiative et dépend des bundles déployés dans l'infrastructure. Il en résulte qu'un « bundle » fournissant un « package » particulier peut être substitué par un autre « bundle » fournissant le même package sans pour autant modifier le « bundle » qui dépend de ce package. Par cette particularité, on peut parler de couplage faible.
Dans le cas d'un « split-package », si un package est exporté par deux « bundles » différents, avec une même version, et que le contenu de ce package diffère entre les « bundles » alors les classes peuvent être dupliquées ou, plus généralement, une partie du « package » est dans un bundle et l'autre partie dans un autre. On établit donc un couplage (contraire à la bonne pratique précédente) qui compromet la manière dont les « bundles » peuvent être étendus et maintenus ; - Utiliser des « bundles » de persistance pour partager les unités de persistance.
Ces « bundles » peuvent être partagés par un grand nombre de clients de persistance basés sur OSGIOpen Services Gateway Initiative. En n'incluant pas directement ce code de persistance et en faisant appel à ces « bundles », ils sont tous hautement cohésifs et facilement réutilisables.
En outre, si plusieurs applications ont besoin d'accéder aux données d'une base de données et que le schéma de cette base de données change, un seul bundle devra être mis à jour.
La gestion centralisée de ces données dans un seul « bundle » constitue également un autre avantage de l'utilisation de « bundles » de persistance puisqu'elle aidera à se prémunir de la corruption de données dans la base.
IV. Exemple d'application▲
En regard des bonnes pratiques énoncées ci-dessus, nous pouvons concevoir un projet basique que nous nommerons « voiture » et qui permettra de gérer les marques et les modèles de voitures qui y sont rattachés.
Nous exposerons dans cette section le diagramme de classes et le diagramme de composants UML de notre projet.
Le diagramme de classes permettra de montrer rapidement la structure de données en montrant les classes qui composeront notre projet.
Le diagramme des composants permet, quant à lui, de décomposer notre projet en composants tout en indiquant les liens entre chacun de ces composants. Cette notion de composant s'applique très bien aux projets OSGIOpen Services Gateway Initiative, car nous pouvons voir chacun des composants de ce diagramme comme un bundle à part entière.
IV-A. Diagramme de classes UML▲
Une marque de voiture possède plusieurs modèles à son catalogue. À une marque est associé au moins un modèle. Par conséquent, le diagramme de classes est extrêmement simple. Il s'agit d'avoir une classe Marque à laquelle est associée une classe Modele comme le présente le diagramme ci-dessous.
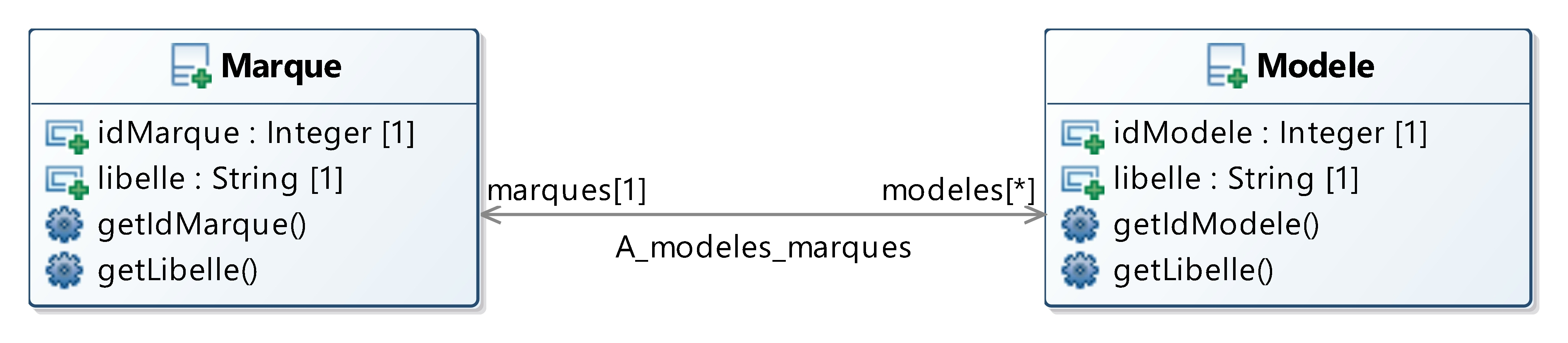
IV-B. Diagramme de composants UML▲
IV-B-1. Partie « Persistance » (couche DAO)▲
Notre projet consistera à sélectionner, ajouter ou supprimer un modèle ou une marque.
Conformément à la dernière bonne pratique évoquée, nous allons créer un composant destiné à gérer la persistance. Il sera nommé « persistence-model » et contiendra la généricité nécessaire à l'évolutivité du projet.
Ce composant contiendra bien sûr notre modèle de donnée. C'est-à-dire qu'il contiendra les classes Marque et Modele.
Ces classes seront des POJO dont hériteront les « entities ». Ces POJO pourront également être hérités par d'autres « entities » en fonction des technologies d'accès aux données utilisées. Dès lors, on sépare le modèle des « entities », ce qui correspond à l'une des bonnes pratiques de OSGI. Ces POJO ne seront pas forcément abstraits, car ils peuvent être utilisés tels quels par une technologie d'accès aux données.
Notre composant gérant la persistance, il convient bien sûr de lui adjoindre les moyens d'accéder aux données en fonction des technologies de persistance existantes. Or, comme évoqué dans les bonnes pratiques, il est nécessaire de séparer l'API de l'implémentation.
Le modèle de données appartient à l'API, il nous faut donc compléter le composant contenant ce modèle par les interfaces nécessaires à la persistance des différentes entités. Ces interfaces seront basées sur des « templates » afin que les classes les implémentant puissent manipuler toutes sortes d'instances de classe (entity) héritant des classes et toujours dans l'optique de rendre notre projet le plus évolutif possible au regard des technologies utilisées et donc des « entities » utilisées.
Afin de simplifier l'évolution du projet, nous créerons une interface de persistance par ressource à gérer.
Dans notre exemple, les interfaces de persistance se nomment ServicePersistenceMarque et ServicePersistenceModele.
Il y aura au moins une implémentation de chaque interface par ressource. En effet, une interface pourra être implémentée par autant de classes qu'on a de technologies de persistance. Parmi ces technologies, on peut citer en exemple JPA, SQL, Cassandra, Elasticsearch…
Dans notre cas, deux composants implémenteront ces interfaces : persistence-marque-jpa-impl et persistence-modele-jpa-impl. Comme leur nom l'indique, ils feront appel à la spécification JPA pour les accès à la base de données.
On respecte ainsi la bonne pratique qui consiste à séparer l'API de l'implémentation.
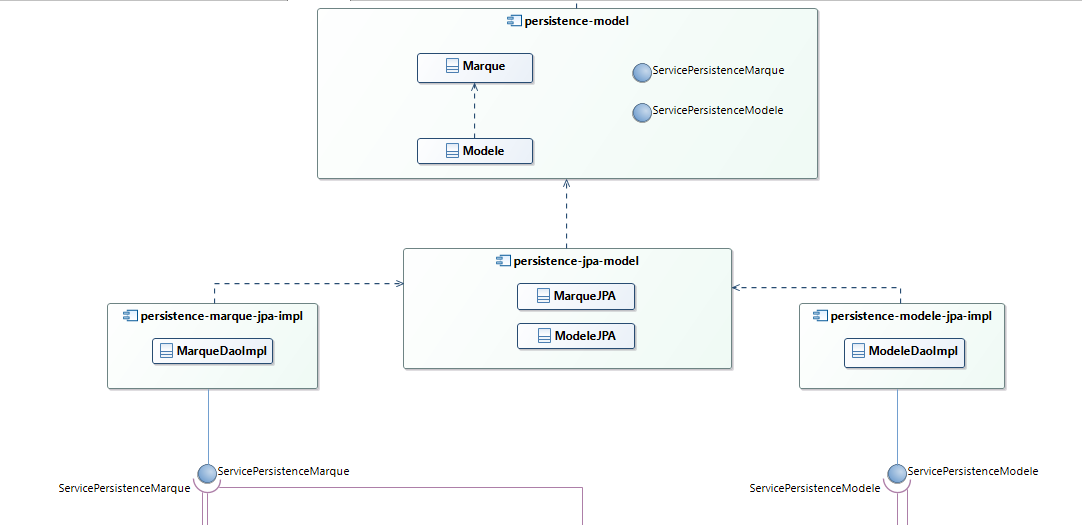
En résumé, la partie persistance de notre projet possédera quatre « bundles » :
- persistence
-model
Ce composant constitue notre API de persistance. Il définit le modèle de données et les interfaces ServicePersistenceMarque et ServicePersistenceModele ;
Ce composant permettra de définir les entités JPA qui hériteront des POJO et et de fournir les fichiers « persistence.xml » et « ehcache.xml » ;- persistence
-marque-jpa-impl
Ce composant est dépendant du bundle persistence-jpa-model et réalise l'interface ServicePersistenceMarque en manipulant l'entité JPA MarqueJPA définie dans le composant et qui hérite du POJO Marque défini dans le composant persistence-model. Il s'agit donc de l'implémentation de l'API ; - persistence
-modele-jpa-impl
Ce composant est dépendant du bundle persistence-jpa-model et réalise l'interface ServicePersistenceModeleen manipulant l'entité JPA définie dans le composant persistence-jpa-model et qui hérite du POJO défini dans le composant . Il s'agit donc, là encore, de l'implémentation de l'API.
Le diagramme de composants de la partie « persistance » du projet est celui-ci :
IV-B-2. Partie « Métier »▲
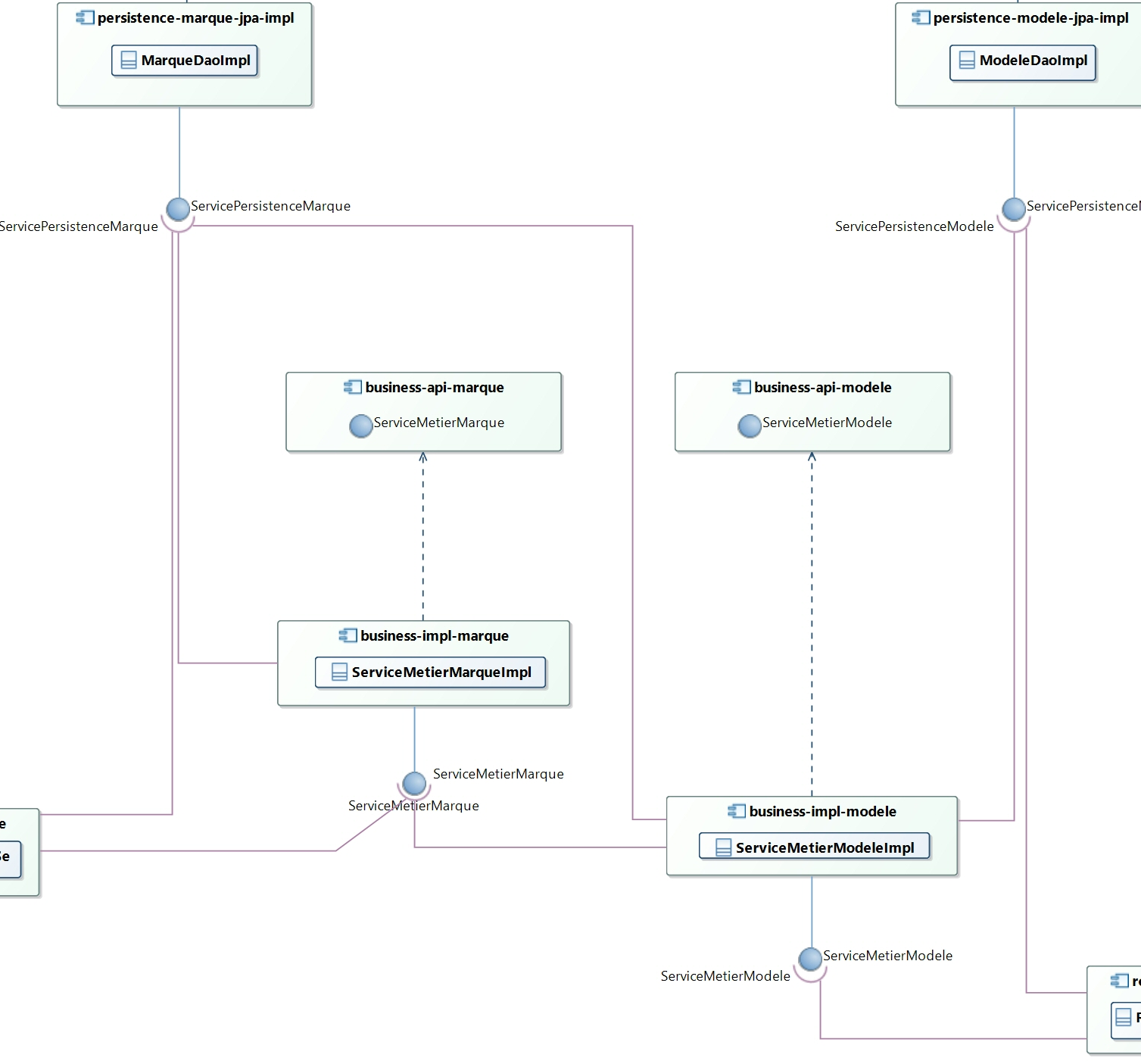
La partie métier s'appuiera sur la partie persistance pour accéder à la base de données.
Ainsi, les « bundles » de persistance seront injectés en tant que service dans les composants de la partie métier.
Les composants de la partie métier utiliseront donc les interfaces de persistance ServicePersistenceMarque et ServicePersistenceModele.
Le bundle assurant la persistance de la ressource Marque sera injecté en tant que service dans le bundle métier de cette même ressource. Ainsi, le bundle de persistance de la ressource Marque fournira la capacité au bundle métier de cette ressource de sélectionner, d'insérer, de mettre à jour et de supprimer une instance de Marque.
De la même manière, le « bundle » assurant la persistance de la ressource Modele sera injecté en tant que service dans le bundle métier de cette même ressource. Ainsi, le bundle de persistance de la ressource Modele fournira la capacité au bundle métier de cette ressource de sélectionner, d'insérer, de mettre à jour et de supprimer une instance de Modele.
Ceci étant, un modèle de véhicule est lié à une marque. Il est donc important que le « bundle » métier de la ressource Modele puisse interroger la base de données afin de récupérer les informations propres à la marque qui est liée à un certain modèle. D'où la nécessité d'injecter le bundle de persistance de la ressource Marque en tant que service dans le bundle métier de la ressource Modele. Cette injection permettra d'effectuer des sélections sur la table Marque. En effet, les sélections ne font pas l'objet d'une logique particulière et ne modifient en rien le contenu des tables en base donc le bundle métier de la ressource Modele pourra se permettre de passer par le bundle persistance de la ressource Marque mais seulement en ce qui concerne les sélections sur la table Marque.
En revanche, nous pouvons envisager de pouvoir créer une marque en même temps que nous créons un modèle. Or, il existe probablement une logique métier à suivre lors de la création d'une marque : par exemple, avant d'insérer un enregistrement dans la table « Marque », il faut vérifier que la marque n'existe pas déjà en base. C'est une logique qui ne dépend pas des « bundles » de persistance mais des « bundles » métier. C'est donc le bundle métier de la ressource Marque qui vérifie cette règle avant d'insérer un enregistrement en base. En conséquence, il est important d'injecter ce bundle métier en tant que service dans le bundle métier de la ressource Modele.
En outre, conformément à la bonne pratique qui stipule de séparer l'API de l'implémentation, il est nécessaire de créer des interfaces métier propres à chaque ressource. Ainsi, nous pourrons modifier l'implémentation sans devoir redémarrer les « bundles » dépendants.
Voici le diagramme de composants correspondant à la partie métier en tenant compte de toutes les considérations énoncées précédemment :
IV-B-3. Partie « Intégration » (couche service)▲
Nous pouvons compléter notre projet par une partie « intégration ».
Cette couche permet aux consommateurs de service d'utiliser les services OSGIOpen Services Gateway Initiative que nous avons définis dans les couches persistance et métier.
L'intégration peut commencer avec de modestes capacités point à point et couvrir le spectre d'un ensemble de routage beaucoup plus intelligent, de conversion de protocole et d'autres mécanismes de transformation.
La partie intégration comporte les éléments auxquels on donne la possibilité d'accéder aux services OSGIOpen Services Gateway Initiative du projet. Elle peut contenir des services RESTRepresentational State Transfer ou SOAPSimple Object Access Protocol, des JMS, des routes…
En ce qui concerne notre projet, la partie « intégration » va contenir des services RESTRepresentational State Transfer (un bundle par ressource afin de garantir la possibilité de modifier indépendamment chaque « bundle » RESTRepresentational State Transfer) dans lesquels nous injecterons les « bundles » métier et persistance en tant que services OSGIOpen Services Gateway Initiative.
Ainsi, nous injecterons, dans le « bundle » RESTRepresentational State Transfer attaché à la ressource Marque, les « bundles » métier et persistance de cette ressource. Le bundle métier permettra l'insertion et la modification d'instances de la ressource alors que le bundle persistance permettra uniquement la sélection de ces instances.
Dans notre exemple, ce service RESTRepresentational State Transfer manipulera des entités JPA, que nous fournirons en paramètre des services métier et de persistance.
Nous pouvons très bien imaginer une autre version de ce service RESTRepresentational State Transfer qui permettra la manipulation d'entités liées à une autre technologie, qui fera la même chose que notre service RESTRepresentational State Transfer ci-dessus tout en appelant les mêmes services métier et de persistance. Seul le type des entités que nous fournirons à ces services sera modifié. Ceci est très pratique pour une mise en production progressive d'une technologie puisqu'on permet à certains clients REST de migrer sur une technologie pendant que d'autres restent encore sur l'ancienne (RAPPEL : en OSGI, des versions différentes d'un même bundle peuvent coexister au sein du framework OSGI).
Le même raisonnement sera appliqué au bundle RESTRepresentational State Transfer de la ressource Modele.
Le diagramme de composants complet est le suivant :
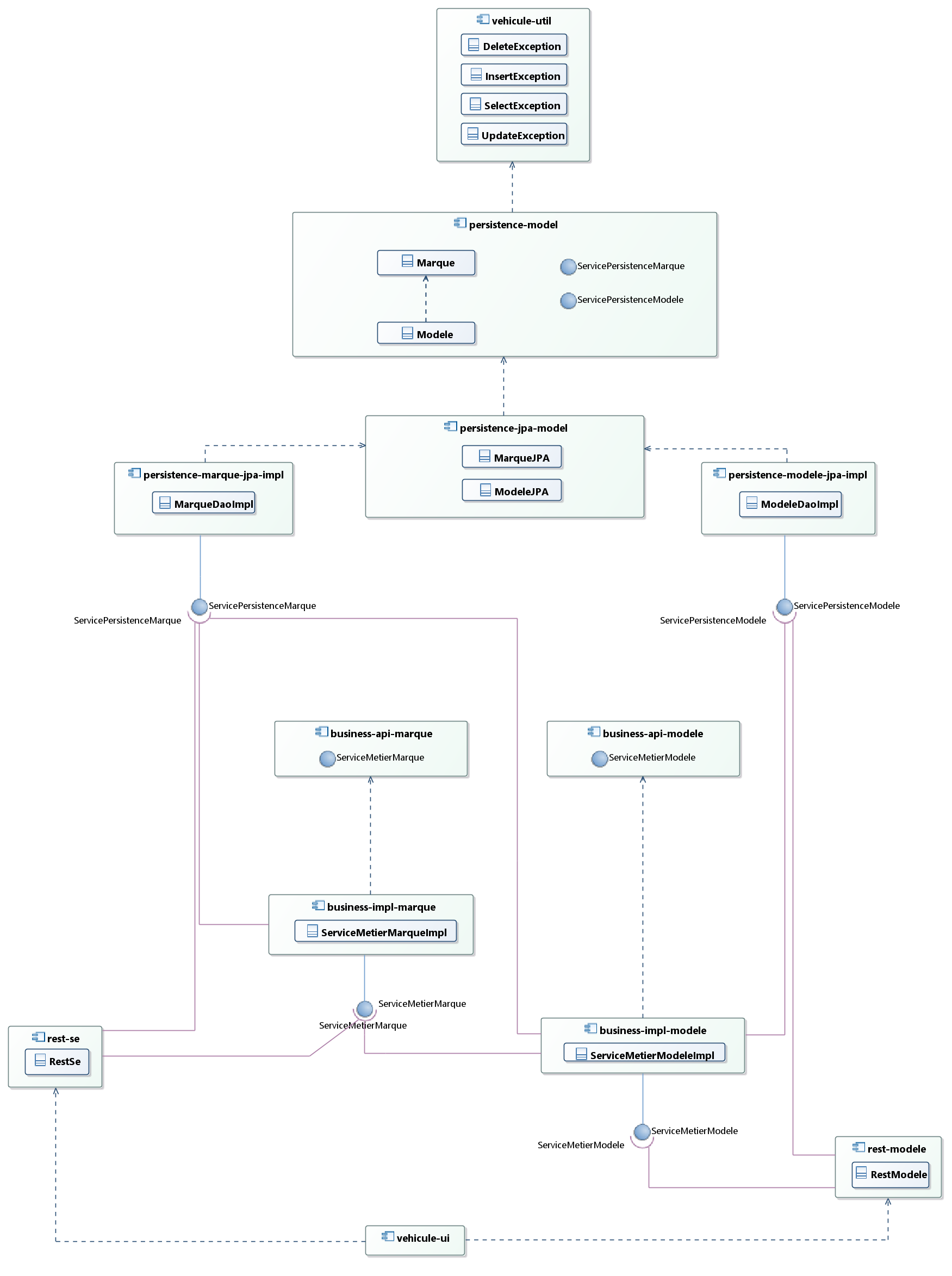
Vous pouvez remarquer qu'apparaît le composant « vehicule-util ». Il s'agit d'un composant dont le rôle sera de fournir des classes permettant :
- de gérer plus finement les exceptions (par exemple, pour retourner les erreurs HTTP adéquates en ce qui concerne les services RESTRepresentational State Transfer) ;
- de définir les classes qui fournissent des « providers » pour jaxrs ;
- …
V. Concrétisation du diagramme de composants en projet Eclipse▲
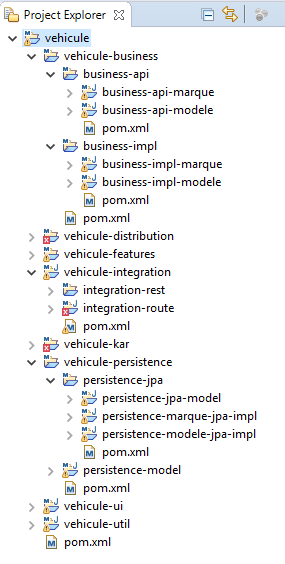
Le passage de la conceptualisation sous forme de diagramme de composants à l'implémentation sous Eclipse de notre projet OSGIOpen Services Gateway Initiative est relativement simple : les composants sont transformés en module Maven dans Eclipse.
Voici l'architecture résultante dans Eclipse :
Les modules Maven suivants généreront autant d'archives « jar » qui constitueront des « bundles » dans Karaf :
-
persistence-modele
Étant donné que nous utilisons JPA, la partie « resources » de ce module contiendra le fichier « persistence.xml ».
En outre, dans notre projet, nous utilisons le cache open source « ehcache » qui nous permet de mettre en mémoire le résultat de certaines requêtes (par appel de la méthode « setHint » de la manière suivante : .setHint( "org.hibernate.cacheable", "true").
Cette mise en mémoire est particulièrement utile en termes de gain tant en temps d'exécution qu'en charge CPU sur la base de données et qu'en bande passante entre l'application et la base de données.Cette mise en cache est conseillée pour les requêtes de sélection fréquentes sur des tables qui n'évoluent pas fréquemment et/ou dont l'impact des mises à jour ne doit pas forcément être retourné rapidement. La durée entre deux mises à jour des informations du cache est paramétrable dans un fichier « ehcache.xml » référencé dans le fichier « persistence.xml » et placé dans le répertoire « resources » du module « persistence-modele » au même titre que le fichier « persistence-xml » ;
-
persistence-jpa-model ;
-
persistence-marque-jpa-impl ;
-
persistence-modele-jpa-impl ;
-
business-api-marque ;
-
business-api-modele ;
-
business-impl-marque ;
-
business-impl-modele ;
-
rest-marque ;
-
rest-modele ;
-
vehicule-ui ;
- vehicule-util.
Au vu de ce projet Eclipse, vous pouvez vous interroger sur plusieurs questions :
-
À quoi servent les sous-modules Maven « vehicule-business », « business-api », « business-impl », « vehicule-persistence », « vehicule-integration », « integration-rest », « integration-route » et « persistence-jpa » ?
Ils permettent simplement de bien distinguer les différentes parties qui composent votre projet OSGIOpen Services Gateway Initiative. Les fichiers pom.xml qui les caractérisent ne contiennent que des références vers les sous-modules qui constitueront, à terme, des « bundles ».Par exemple, le module Maven « business-api » référence les modules « business-api-marque » et « business-api-modele » dans son fichier « pom.xml » :
pom.xmlSélectionnez1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>fr.exemple</groupId><artifactId>vehicule-business</artifactId><version>0.1.0</version></parent><artifactId>business-api</artifactId><packaging>pom</packaging><modules><module>business-api-marque</module><module>business-api-modele</module></modules></project>Rien ne vous oblige à créer ces modules, mais votre projet serait nettement moins clair au premier coup d'œil si vous n'utilisez pas cette méthode.
-
Que sont les modules « vehicule-kar », « vehicule-features », « vehicule-distribution » ?
Certains d'entre vous, qui ont lu le tutoriel « Tutoriel pour développer et déployer un service Web RESTFUL OSGI multibundle sous Eclipse et Karaf » ont déjà la réponse.
Il s'agit des modules Maven qui nous permettent de créer les dispositifs permettant de déployer notre projet sous Karaf. Plusieurs dispositifs s'offrent à vous pour déployer un projet sous Karaf :-
une archive « kar »
Il s'agit d'un fichier « zip » mais avec l'extension « kar » contenant :- un répertoire « repository » (comme dans Maven) ;
- les artefacts de notre projet qui constituent des « bundles » ;
- la « feature » de notre projet ;
- une feature
Il s'agit d'un fichier XML qui décrit notre application. Y figurent tous les artefacts qui constituent les « bundles » et qui doivent être déployés dans Karaf ; - une distribution personnalisée
C'est la manière la plus simple et la plus rapide pour installer votre projet. Il s'agit d'une distribution de Karaf que vous dézippez comme vous le faites après avoir téléchargé n'importe quelle distribution de Karaf. La seule différence est que votre projet est déjà installé et configuré à l'intérieur. La seule chose que vous avez à faire pour démarrer votre application est de dézipper la distribution et d'exécuter Karaf.
-
REMARQUE : nous vous invitons à lire la section « Déploiement de l'application dans Karaf » du tutoriel « Tutoriel pour développer et déployer un service Web RESTFUL OSGIOpen Services Gateway Initiative multibundle sous Eclipse et Karaf » ici pour plus d'informations sur le déploiement d'une application sous Karaf.
La solution de déploiement présente n'étant pas forcément celle qui sera utilisée dans le futur, nous vous conseillons de développer, dès le début de la phase de développement de vos projets, les modules respectifs pour la création d'une archive « kar », d'une feature et d'une distribution personnalisée. Le développement de ces trois modules est extrêmement rapide (voir le code source). La création de ces « kar », « feature » et distribution personnalisée se fait lors de la compilation du projet et est donc complètement transparente.
Afin de nous faciliter la tâche, nous avons d'abord, dans notre exemple, généré le fichier « feature » en remplissant convenablement le fichier « pom.xml » du module « vehicule-features » et en utilisant le « karaf-maven-plugin ».
Par la suite, à l'aide de ce fichier « feature », nous créons une archive « kar » en référençant cette « feature » dans le fichier « pom.xml » du module « vehicule-kar » et en utilisant encore le plugin Maven « karaf-maven-plugin ».
Ensuite, nous créons la distribution personnalisée de Karaf en renseignant, dans le fichier « pom.xml » du module « vehicule-distribution », la « feature » générée précédemment et toutes les « features » nécessaires à la bonne exécution de notre projet (les « features » standards + les « features » hibernate, hibernate-ehcache, jdbc, jpa, transaction et jndi propres à notre projet).
REMARQUE : rappelez-vous que, dans le tutoriel « Tutoriel pour développer et déployer un service Web RESTFUL OSGI multibundle sous Eclipse et Karaf », nous avions d'abord créé l'archive « Kar » avant d'en extraire la « feature ». Ce sont deux façons de faire différentes, mais celle qui consiste à créer la feature puis l'archive « kar » nous semble plus simple.
Il est important de noter que vous pouvez générer autant de distributions personnalisées de Karaf qu'il y a de modules « métier », « intégration » et « persistance » dans votre projet. Cette hypothèse peut être envisagée dans le cas où les serveurs Karaf doivent être placés sur des serveurs physiques différents pour optimiser les charges par exemple. Dans ce cas, vous créerez autant de modules « distribution » que vous aurez de distributions personnalisées de Karaf. Chacune des distributions pourra embarquer un ou plusieurs modules.
VI. Code source de l'exemple ▲
VI-A. Création des tables dans la base de données ▲
Dans la base de données PostgreSQL, il est nécessaire d'exécuter le script SQL ci-dessous permettant de créer les tables nécessaires à l'exécution de l'exemple décrit tout au long de ce tutoriel :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
CREATE DATABASE exemple
WITH
OWNER = postgres
ENCODING = 'UTF8'
LC_COLLATE = 'French_France.1252'
LC_CTYPE = 'French_France.1252'
TABLESPACE = pg_default
CONNECTION LIMIT = -1;
CREATE SCHEMA vehicule
AUTHORIZATION postgres;
CREATE TABLE vehicule.marque
(
idmarque integer NOT NULL DEFAULT nextval('vehicule.marque_idmarque_seq'::regclass),
libelle character varying(128) COLLATE pg_catalog."default" NOT NULL,
CONSTRAINT pk_marque PRIMARY KEY (idmarque)
)
WITH (
OIDS = FALSE
)
TABLESPACE pg_default;
ALTER TABLE vehicule.marque
OWNER to postgres;
CREATE TABLE vehicule.modele
(
idmodele integer NOT NULL DEFAULT nextval('vehicule.modele_idmodele_seq'::regclass),
libelle character varying(128) COLLATE pg_catalog."default" NOT NULL,
marque_id integer,
CONSTRAINT pk_modele PRIMARY KEY (idmodele),
CONSTRAINT marquefk FOREIGN KEY (marque_id)
REFERENCES vehicule.marque (idmarque) MATCH FULL
ON UPDATE NO ACTION
ON DELETE NO ACTION
)
WITH (
OIDS = FALSE
)
TABLESPACE pg_default;
ALTER TABLE vehicule.modele
OWNER to postgres;
VI-B. Code Java de l'exemple ▲
Le code source de l'exemple dont il est question dans ce tutoriel est disponible à l'adresse suivante : olivier-rozier.developpez.com/tutoriels/osgi/structure-projet/sources/vehicule.zip
L'importation de ce projet dans Eclipse s'effectue de la même manière que dans notre précédent tutoriel. Vous trouverez cette procédure à cette adresse : https://olivier-rozier.developpez.com/tutoriels/rest/restful-karaf-multibundle/#LX-Brozier.developpez.com/tutoriels/rest/restful-karaf-multibundle/#LX-B
Pensez à modifier le fichier « /etc/org.ops4j.datasource-exemple.cfg » pour prendre en compte les informations d'accès à votre base de données.
Vous trouverez, dans ce projet, le module Maven « vehicule-ui » qui contient toute la partie « interface utilisateur », réalisée avec AngularJS, afin de gérer nos deux tables en utilisant les services RESTRepresentational State Transfer. Les fonctionnalités de cette interface utilisateur sont les suivantes :
- ajout, modification, suppression d'une marque ;
- ajout, modification, suppression d'un modèle.
En outre, il faut noter que, dans ce projet, nous avons tenu à utiliser une fonctionnalité de JAX-RS qui est fort peu connue et qui consiste à consommer, dans un service RESTRepresentational State Transfer, les requêtes de type « multipart/form-data ». Afin que vous puissiez mettre en œuvre cette fonctionnalité assez rapidement, nous avons trouvé intéressant de vous l'exposer en vous fournissant un exemple. Il est ainsi possible, dans un service RESTRepresentational State Transfer, de récupérer dans la requête qui lui est adressée, un certain nombre d'objets de types pouvant être différents (json, xlm, fichier…).
Ainsi, nous avons permis au service RESTRepresentational State Transfer « RestModele » de recevoir une requête « multipart/form-data » via la méthode POST afin de pouvoir créer, en même temps (en utilisant la même interface graphique), et la marque de véhicule, et un modèle de cette marque. Cette fonctionnalité est exposée sur le site officiel traitant de JAXRS : http://cxf.apache.org/docs/jax-rs-multiparts.html
L'interface utilisateur en angularJS est relativement succincte et consiste uniquement à montrer un moyen d'appeler les services RESTRepresentational State Transfer : ce n'est pas le but de ce tutoriel de s'attarder sur cette interface.
Afin de faire afficher l'interface graphique, il vous faudra saisir l'adresse http://votre_adresse_ip:8181/vehicule-console
VII. Conclusion▲
Nous venons de voir comment créer un projet OSGIOpen Services Gateway Initiative, dans son ensemble, qui soit évolutif et performant. Les points cruciaux à retenir sont le respect des bonnes pratiques inculquées par l'alliance OSGIOpen Services Gateway Initiative. Parmi elles, notez le bannissement des surcouches applicatives qui alourdissent non seulement le code, mais aussi les performances tout en générant un nombre croissant de dépendances qui réduisent le caractère « atomique » qu'un « bundle » doit avoir et qui, par la même occasion, accroissent la difficulté à réutiliser ce « bundle ».
Aussi, demandez-vous, avant d'utiliser un framework supplémentaire, ce qu'il vous apporte en termes :
- de performances d'exécution ;
- de facilité de maintenance et d'évolution ;
- d'utilité (est-ce que vous ne pouvez pas éviter son utilisation en ajoutant quelques lignes à votre programme ?).
Je tiens à remercier Jean-Baptiste Onofré pour ses très bons conseils liés à la mise en œuvre des bonnes pratiques OSGIOpen Services Gateway Initiative, pour sa sympathie et sa relecture technique de cet article ainsi que Mickaël Baron pour la relecture technique et son enthousiasme et f-leb pour sa relecture orthographique et sa promptitude.